系统设计基础
CAP定理
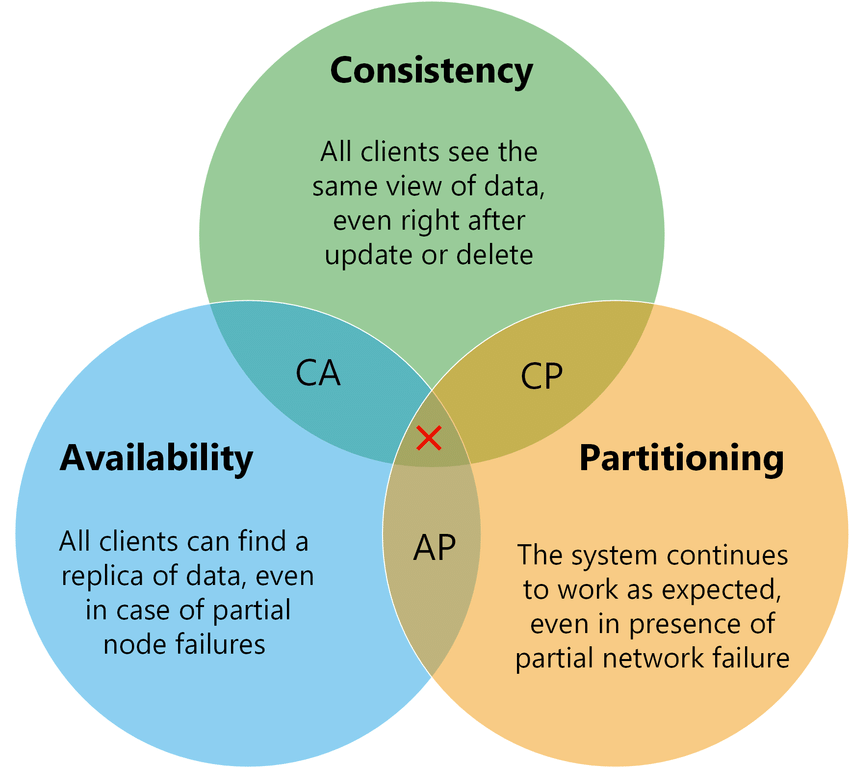
CAP定理,或称为Brewer定理,指出分布式数据库系统只能保证三个特性中的两个:一致性、可用性和分区容忍性。系统优先考虑可用性而非一致性,可能会响应可能过时的数据。
Partition Tolerance
在CAP理论中,Partition Tolerance(分区容忍性)是指系统在发生网络分区故障的时候,仍然能够对外提供服务的能力。
所谓网络分区故障,是指系统中的节点被分成两部分,节点间的网络通信被阻断。在这种情况下,一个分布式系统可能会表现出下面两种行为:
无法对外提供服务 整个系统不可用,对用户不可见。
以牺牲一致性为代价继续服务 系统继续对用户可见,但返回的数据可能不一致。
Partition Tolerance表示系统能够承受网络分区的发生,继续对外服务而不会完全崩溃。根据CAP理论,一个系统不可能同时满足一致性(Consistency)、可用性(Availability)和分区容忍性,最多只能同时满足两个。
所以一个Partition Tolerance系统通常会牺牲数据一致性来保证服务可用性。比如允许读取到过期数据,或两个分区的数据产生冲突。这在许多大规模分布式系统中都是可接受的权衡。
一个典型的Partition Tolerance(分区容忍性)的例子是DNS系统。
DNS采用了分布式的树形结构,一个域名由多个DNS服务器共同提供解析服务。当网络发生分区时,可能出现如下情况:
某区域用户无法访问部分DNS服务器,但可以访问到另一部分服务器,仍能得到域名解析结果。
不同的DNS服务器返回了不同的解析结果(IP地址不一致),但用户还是能得到响应。
这就是DNS系统表现出来的Partition Tolerance性质。当网络分区发生时,DNS系统为了继续服务,承受返回不一致数据的结果,而没有选择完全停止响应。
Partition Tolerance的另一个例子是一些分布式缓存系统,如Memcached。当节点间失去联系时,不同分区的数据可能不一致,但每个分区内部仍能继续使用本地缓存,整个系统不会完全停止服务。
这些系统都采用了设计理念:”允许读取脏数据”或者”允许短暂不一致”来实现Partition Tolerance。因为对大多数应用来说,与整个系统完全不可用相比,读取到陈旧或不一致的数据仍是可以接受的。
现代分布式系统组件
负载均衡器
负载均衡器是Web应用程序的入口点。它将传入的客户流量分配到不同的工作节点/服务器。它可以帮助:
- 避免单个服务器过载
- 当一个服务器不可用时,将请求重定向到健康的服务器。
负载均衡器在使系统能够水平扩展方面发挥着重要作用。AWS提供以下负载均衡器服务:
- 经典负载均衡器:主要用于将流量分配到EC2实例
- 应用负载均衡器:更灵活,默认选择这个。
- 网络负载均衡器
- 网关负载均衡器
CDN
内容分发网络(CDN)是第三方提供的快速文件交付服务。通过提供单一端点,CDN服务将自动路由到最近的服务器获取静态文件。它主要用于提供静态文件,如HTML、JavaScript文件和图像。它还可以托管一些文件,如视频、压缩包等。它可以:
- 减轻Web服务器的负载
- 通过从最近的服务器获取文件来加速文件检索。
CDN需要设置TTL(生存时间)。如果TTL设置为较小的值,它将需要经常从源更新缓存,数据传输的费用将增加。如果TTL设置为较大的值,客户可能会获取过时的文件。TTL应根据系统需求设置。
DNS
域名系统(DNS)是一个将域名转换为互联网协议(IP)地址的数据库。DNS将人们用来定位网站的名称映射到计算机用来定位该网站的IP地址。

Web层
Web层主要指Web服务。Web服务主要包含业务逻辑。如从数据库获取数据并返回给用户,或代表用户提交订单等。理想情况下,Web层应该是无状态的,因为这可以使Web层更容易水平扩展。
数据层
数据层主要指数据库或持久存储。”持久”意味着即使服务器关闭,数据也不会丢失。相反,一些内存缓存系统如果服务器关闭,将丢失所有数据。随着数据变得越来越复杂,人们开发了各种数据库系统来适应不同的用例。
- 关系型数据库
- NoSQL(不仅仅是SQL)
在这里详细描述数据库太过雄心勃勃,我们将用单独的文章详细讨论它。
缓存层
缓存层的出现是因为查询数据库是一个昂贵的操作。同时,一些请求也可能很昂贵,比如运行模型进行计算。多亏了局部性原理,我们知道处理器在短时间内重复访问同一组内存位置的趋势。这意味着同一数据可能在短时间内被多次使用。这使得缓存层在实际生产中很有用。缓存作为系统内的中间件工作,可以独立扩展。它也带来了一系列挑战,如缓存过热、缓存未命中和数据同步。与数据层一样,我们将用单独的文章详细讨论它。

消息队列
有时我们可能会考虑是否存在服务调用链。这些子系统如何独立扩展。例如,如果服务A试图调用服务B,如果服务B在服务A发出调用时不可用,那么服务A必须等待,否则我们将丢失来自客户的请求。我们可能希望有一些东西可以抽象服务的输入生产者和结果消费者。这就是消息队列发挥作用的地方。
消息队列作为临时存储服务。生产者可以向MQ发布消息,无论消费者是否工作。同时,消费者可以从MQ消费消息,无论生产者是否工作。
